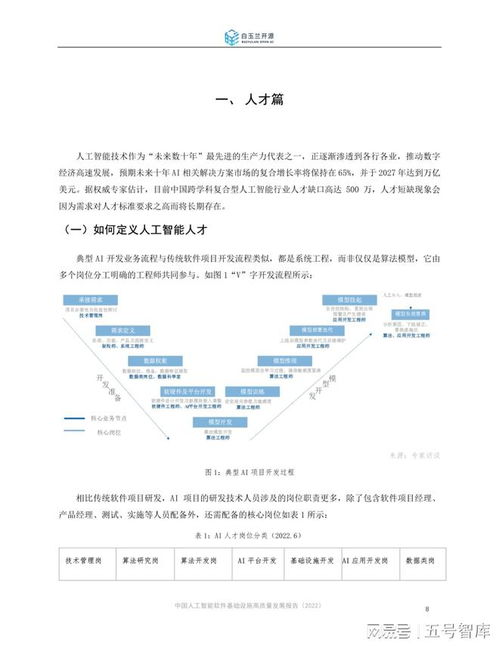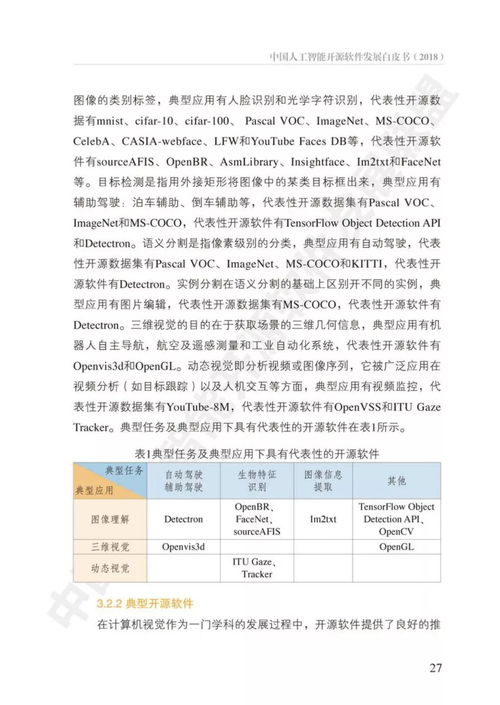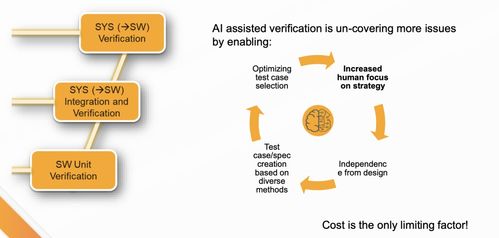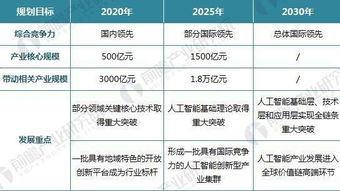
以深度學習為代表的人工智能技術正以前所未有的速度重塑世界,一場深刻的“AI革命”已全面展開。這場革命不僅體現為圖像識別、自然語言處理等領域的性能飛躍,更在于其催生了全新的產業形態、研究范式與基礎軟件生態。本報告將聚焦深度學習驅動的AI革命,并深入剖析支撐其發展的基礎軟件開發前沿進展。
一、深度學習:AI革命的核心引擎
深度學習通過構建包含多層非線性變換的神經網絡模型,能夠從海量數據中自動學習層次化的特征表示,從而解決過去難以應對的復雜模式識別問題。其成功主要歸功于三大要素:大規模數據、強大算力(尤其是GPU/TPU等專用硬件)以及算法創新。從AlphaGo的橫空出世,到GPT系列、DALL-E等大模型的涌現,深度學習已從實驗室走向千行百業,成為推動自動駕駛、智慧醫療、金融科技、內容生成等領域變革的核心技術。這場革命的特征是“智能化”的普適化與平民化,AI正從專用工具轉變為通用能力基礎設施。
二、人工智能基礎軟件:生態基石與創新前沿
AI,尤其是深度學習的蓬勃發展,離不開底層基礎軟件棧的強力支撐。這一軟件棧構成了從理論算法到產業應用的“轉化橋梁”,其發展水平直接決定了AI創新的效率與邊界。當前,AI基礎軟件開發呈現出以下關鍵趨勢與前沿方向:
1. 框架與編譯器:走向高性能與統一化
以TensorFlow、PyTorch、JAX等為代表的深度學習框架,通過提供靈活的編程接口和自動微分等核心功能,極大降低了模型研發門檻。前沿進展正聚焦于:
- 高性能計算與編譯優化:如MLIR(Multi-Level Intermediate Representation)、TVM等編譯器技術,致力于將高級模型描述自動優化并部署到CPU、GPU、NPU乃至各類邊緣設備,實現“一次編寫,隨處高效運行”。
- 動態與靜態圖的融合:結合PyTorch的動態圖易用性和TensorFlow靜態圖的部署優化優勢,追求開發靈活性與運行效率的統一。
- 分布式訓練規模化:支持千卡乃至萬卡集群的穩定高效并行訓練,是訓練百億、千億參數大模型的關鍵。
2. 模型管理與部署:MLOps的工業化實踐
隨著模型生命周期管理的復雜化,MLOps理念應運而生,旨在實現AI模型的持續集成、持續交付與持續監控。相關基礎軟件包括:
- 模型倉庫與版本管理:如MLflow、Weights & Biases,用于跟蹤實驗、管理模型版本和元數據。
- 自動化流水線:如Kubeflow、TFX,將數據預處理、訓練、驗證、部署流程自動化。
- 在線服務與推理優化:如Triton Inference Server,提供高性能、多框架的模型服務化能力;通過模型剪枝、量化、知識蒸餾等技術壓縮模型,以滿足邊緣端低延遲、低功耗的部署需求。
- 數據與開發工具鏈:提升質量與效率
- 數據治理與版本控制:如Delta Lake、DVC,確保訓練數據的一致性、可追溯性與可復現性。
- 自動化機器學習(AutoML):通過NAS(神經架構搜索)、超參數優化等工具,部分自動化模型設計過程,降低對專家經驗的依賴。
- 交互式開發與可視化:Jupyter Notebook的普及以及更豐富的模型調試、可視化和可解釋性工具(如Captum、TensorBoard),增強了開發過程的透明度和可控性。
4. 開源與標準化:構建協同生態
開源是AI基礎軟件發展的主旋律。從框架到工具,開源社區加速了技術迭代與知識共享。ONNX(開放神經網絡交換格式)等標準致力于實現不同框架間模型的互操作性,避免生態鎖定,促進工具鏈的健康發展。
三、挑戰與未來展望
盡管成就顯著,AI基礎軟件開發仍面臨諸多挑戰:系統復雜性劇增(軟硬件協同設計)、安全與可信賴性(對抗攻擊、隱私保護)、能源效率(大模型訓練的巨大碳足跡)以及人才缺口。我們預期:
- AI原生基礎設施:云計算將進化為“AI云”,提供從硬件、框架到模型服務的一體化、垂直優化的AI基礎設施。
- 智能化編程:AI將更多地用于輔助甚至主導軟件開發(如代碼生成、調試),基礎軟件本身將變得更加“智能”。
- 軟硬件深度協同:針對Transformer等主流架構的專用硬件及配套編譯器將成主流,追求極致的性能功耗比。
- 重視可靠性與治理:伴隨AI應用深入社會,基礎軟件將內置更多關于公平性、可解釋性、魯棒性和安全性的支持與審計工具。
###
深度學習掀起的AI革命方興未艾,而其持續深化與廣泛賦能,高度依賴于一個健壯、高效、易用的基礎軟件生態。這一領域的創新已從單一的框架競爭,演變為涵蓋開發、部署、運維、治理的全棧競爭與合作。持續投資并突破AI基礎軟件的關鍵技術,不僅是搶占技術制高點的需要,更是確保AI革命成果能夠穩健、公平、可持續地惠及全社會的基石。